Menu
Articles /Pin to ProfileBookmark
How to Identify Content Refresh Candidates, In Detail

(Editorial note: I originally wrote this post over on the Hit Subscribe blog. I’ll be cross-posting anything I think this audience might find interesting and also started a SubStack to which I’ll syndicate marketing-related content.)
For my first blog entry on 2024’s ledger (BTW, happy new year!) I’m going to do a little double-duty. As you can see from a little slice of my Asana task list, I owe our account managers an updated SOP for identifying client refresh candidates.
However, since it’s that time of year when everyone’s “best tools of 2023” listicles start to age like milk, I figure our account managers aren’t the only people that might have use for a primer on identifying content refreshes. So this is both an SOP for them and a blog post for everyone because, well, why not?
A Brief Definition of Content Refreshes and Their Value Prop
Before diving in, I’d be remiss not to provide a little context. First, when I talk about refreshing content, I mean quite simply modifying any previously published piece of content on a site. The nature of those edits will generally involve updating the article with additional, more current information (hence “refresh”).
As a quick example, consider this post about content managers that I wrote back in 2020. In it, I talk about being a blogger for ten years, which is no longer true. So I could “refresh” it by going in and correcting that to thirteen years…and then applying for AARP.
As for why you would do this, hobbyists might do it for a purist’s love of correctness. But in the business world, the main motivation is generally to preserve or increase traffic to the content, usually from search engines.
Search Engines and Content “Freshness”
At this point, I’m going to ask you to set aside your preconceived notion that “Google ‘likes’ fresh content,” if you have it. Anthropomorphizing the search engine isn’t helpful for our purposes here. There’s a less magical and more grounded explanation for executing refreshes.
On a long enough timeline, nothing you publish is truly evergreen. If you publish some kind of viral hot take, you’ll get views for a week, then nothing, in what the SEO industry refers to as the “spike of hope and flatline of nope.”
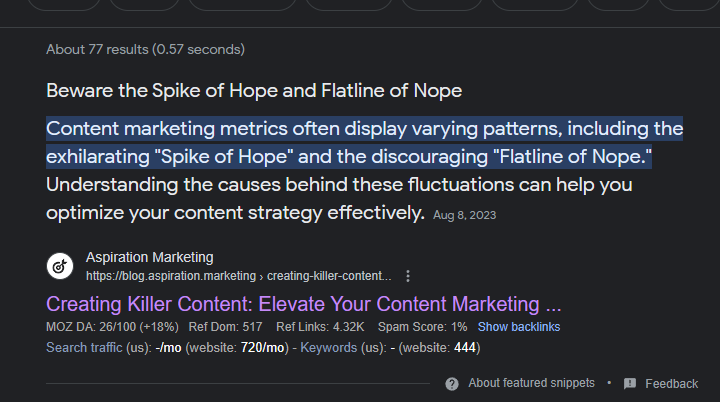
But if you target keyword ranking and search engine traffic, you’ll typically have a lifecycle where traffic to your post gradually increases for maybe a year or two and then gradually decays over several years. I describe that in a lot more detail in this post about modeling organic traffic. The decay will come, and the best you can hope for is a gentle slope when it does.
Enter the refresh.
A content refresh aims to slow the decay or even temporarily restore traffic growth. By routinely modifying posts to maintain the latest information on their topic, you ensure that searchers continue to find the content valuable, prompting the search engine to continue to rank the article and bring traffic to it.
I should note that, for the rest of this post, I’m going to assume that whoever is executing a refresh is doing so in an SEO-best-practice way, without going into detail about what that looks like. This post is already long enough without that digression.
Factors
So why not just routinely and obsessively refresh all of your content, as a sort of traffic decay prophylactic? Well, setting aside the obvious issue of cost/labor, especially for high-volume content sites, let’s now consider the variables involved in deciding when to execute a refresh.
To do this, I’ll do what I specialize in: ruin the art of content with math. I’ll briefly identify the factors to consider when looking for refresh candidates. From there, each section below will get “mathier” as we go, allowing you to bail out when you’ve had enough.
Here are the factors that impact the decision of whether or not to refresh a post:
- Content age
- Current content accuracy
- Content traffic potential
- Cost of refreshing
- Potential value of refreshing
- Traffic trend
- Risk tolerance vis a vis current traffic
And generally speaking, we want a process that takes relevant factors into account and first compiles a list of candidates for refresh. There will then generally be a secondary process to evaluate the candidates, prioritizing and/or culling them.
For our account managers, this is generally as simple as gathering refresh candidates and having the client approve. If you control all of the content, the prioritization process will generally account for cost and prioritize based on potential gains.
I realize this is all abstract, but don’t worry. The 101 treatment of this will serve as a simple, concrete example.
Refresh Identification and Curation 101: A Simple Process for Our Account Managers
I’m going to start with the process, and then explain the rationale. Here’s a dead simple summary of the two things we need to do:
- Find any obviously outdated blog posts via a title search.
- Find any blog posts ranking between positions 4 and 15 for their “best” keyword.
Identification Step-By-Step
You’re going to make this list in two passes and later eliminate any duplicates you find.
First, find the obviously outdated post. You do that with an advanced Google search:
site:{targetsite} intitle:2023|2022|2021|2020|2019Here’s what this would look like against the New York Times, for instance:
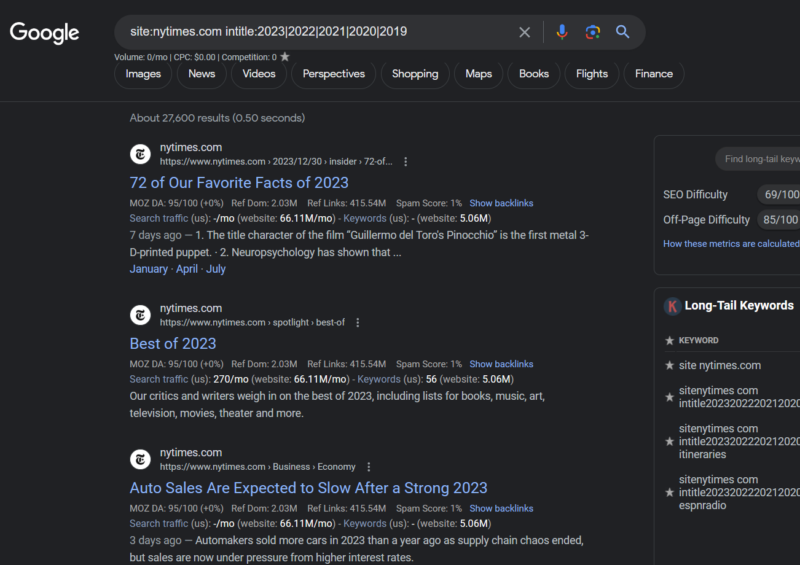
This will give you a list of any pieces of content on the site with a previous year in the title—a common occurrence with listicle-type articles that will need refreshing. You’ll want to add these URLs to a spreadsheet of candidates.
Next up, let’s find articles ranking between 4 and 15. To do this, you’ll log into Ahrefs and use site explorer on the target site, navigating to “top pages.” Here’s what that looks like for our property, makemeaprogrammer.com.
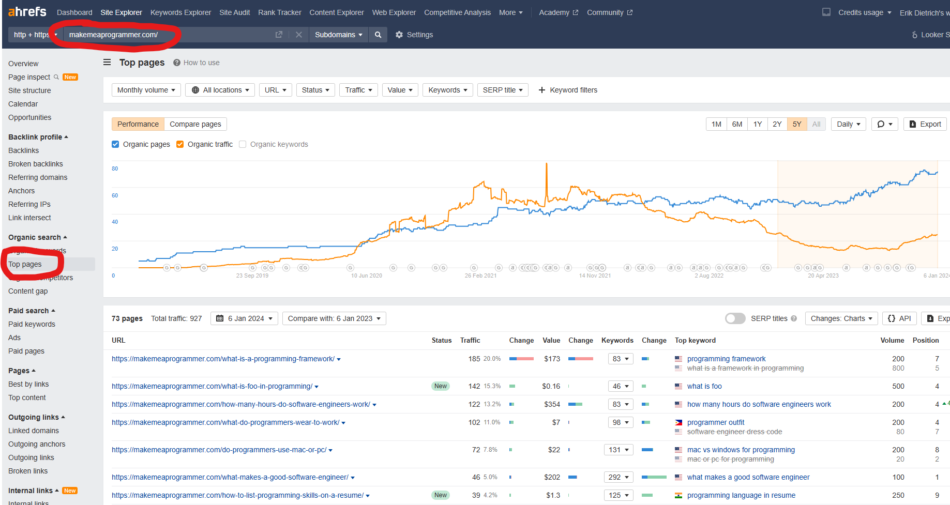
Now, you’re going to click on “+keyword filters” and filter by position, entering 4–15.
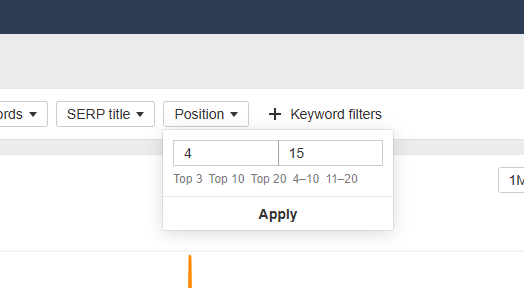
Apply the filter, and let ‘er rip. This will result in a list of URLs that occupy a position between 4 and 15 for what Ahrefs considers to be the URL’s “best” keyword. Click export, and this list of URLs is added to our candidates list.
From here, paste the Ahrefs Excel export into a Google sheet and add any URLs from the outdated title search that aren’t already in there. This is our candidate list.
If You Don’t Have Ahrefs
Our account managers all have this, but if you don’t, you can still implement the spirit of the activity. The easiest thing to do would be to comb this list of SERP trackers for an inexpensive one or one with a free trial and use it to find rankings for your site.
But you can also accomplish this manually by taking the pages on your site that earn search traffic and simply googling their best keyword, noting where you come up.
Prioritizing and Culling
With a candidate list in place, we need to cull, then prioritize. For us, it’s ultimately up to the client what to refresh, but we certainly want to go to them with a curated, prioritized list and a set of recommendations.
Here’s how we cull, going through the list one by one:
- If the article has been modified in the last six months, remove it as a candidate.
- If an article with a year in the date is obviously about some temporal event (e.g., “Our trip to WhateverCon, 2023”), remove it as a candidate.
- If the article is unrelated to the keyword (e.g., an article about semi trucks ranks for the name of a random truck driver that the article happens to mention), remove it as a candidate.
With everything culled, we now prioritize, which is also dead simple in the 101 edition. Sort by “Current Top Keyword: Volume,” descending.
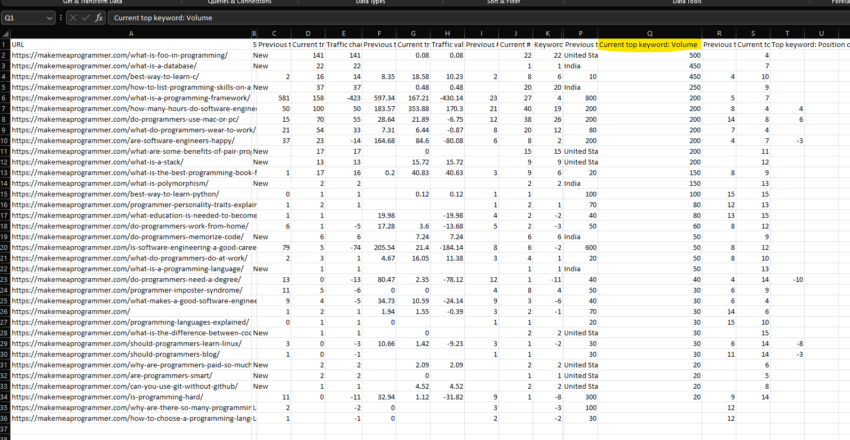
We now have a prioritized list of refresh candidates ready to present and/or execute.
The Rationale
Let’s pause now and revisit the factors I mentioned above in considering why this approach makes sense.
- Anything with a previous year in the title is now inaccurate and thus going to plummet in traffic, if it hasn’t already. The risk of a refresh here is nil, and the potential upside is high.
- We want to ignore any article ranking below position 15, since there’s a very high chance that it has no traffic and isn’t capable of earning any. This way, we don’t waste time or money on a pointless refresh with no upside value.
- We want to ignore any article ranking above position 4 since it’s successfully ranking already. As they say, “Don’t mess with success” (the risk factor is high).
- We want to hold off on any article touched within the last six months because the effort may be wasted, especially with newly published articles. It takes a while for things to settle into their eventual ranking position, and if you fiddle too much, it might be pointless labor.
So, at the 101 level, we have a generally low-risk, high-upside way to productively identify and execute content refreshes. In other words, you can be confident that following this process will yield good results, without worrying too much about underlying data and probabilities.
Refresh Identification 201: Traffic Trends
To explain the rationale for the more in-depth approaches, I need to explain a little bit about probability and game theory. Enter the math.
Refreshes as Blackjack Hands
Whenever you refresh a live piece of content, you’re expecting it to rank better and earn more traffic. And this is usually what will happen. But sometimes, for whatever reason, it will actually drop in rankings and traffic.
So every time you touch a post, you do so knowing that it will probably help but knowing it might instead hurt. You want to do it anyway because the expected value of the activity is positive. It’s more likely to help than hurt, so you live with the handful of times it hurts while trying to minimize the impact of the “hurts.”
Think of this as a blackjack game where you’re the casino. You play the game knowing that you won’t win every hand but knowing that you will win more than you lose. The idea, then, is to play lots of hands, stacking the “win more than lose” and minimizing the impact of chance.
This is the real reason for the “4–15” ranking heuristic above. A losing hand of a refresh is a lot less of a bummer for an article ranking in position 12 than for one ranking in position 1, but a winning hand can rocket you up the ladder.
Expanding the “Nothing to Lose” Umbrella
But raw ranking is really just a reductive shortcut for evaluating risk (whether we have much to lose or not). There are other scenarios in which we have nothing to lose (or gain):
- What if a piece of content ranks #1 for a term but has been steadily declining in traffic?
- What if a piece of content ranks, say, 5th for a term, but the term has no volume, and the post earns no traffic?
Our previous approach would ignore the first situation, even though it calls for a refresh, while executing a pointless refresh in the second situation.
To drive this home, let’s return to Make Me a Programmer. At the time of writing, it ranks #1 (below a featured snippet) for “git without github.”
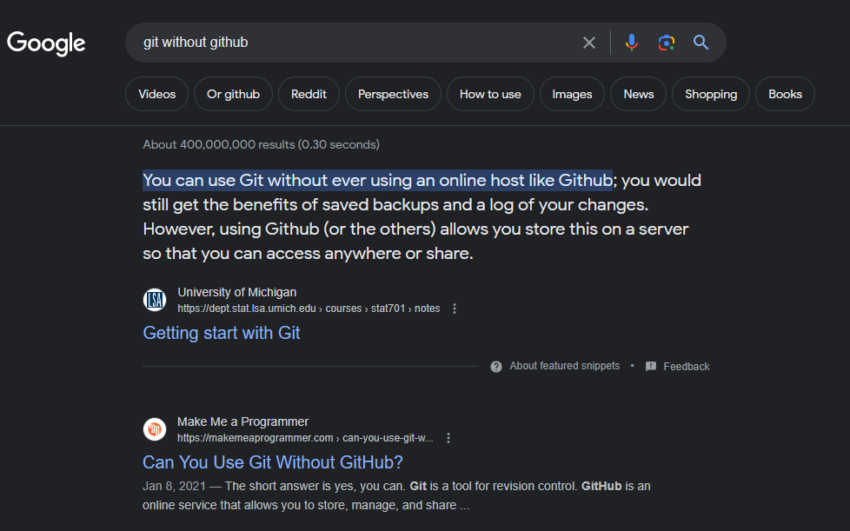
But take a look at its month-over-month traffic. It’s declining, potentially because of that UMich-featured snippet in the mix:
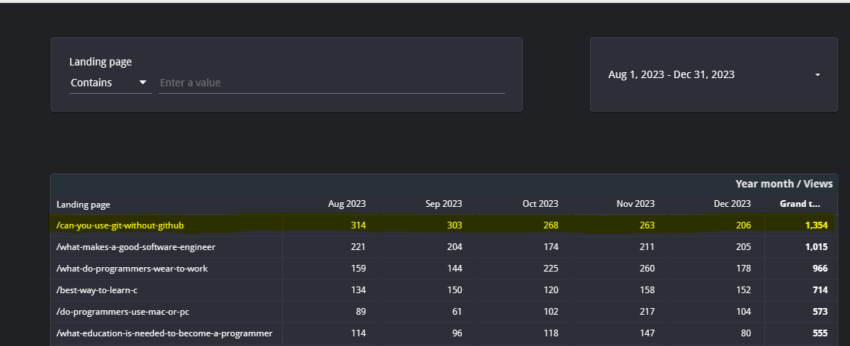
“Don’t mess with success” doesn’t apply here because losing more than 30% of its traffic is hardly success. This is a situation where I’d do a refresh, particularly with a mind toward earning that featured snippet.
On the flip side, at the time of writing, Make Me a Programmer ranked fifth for the term “what non programming skills do programmers need” (counting various SERP widgets as occupying positions). And yet, in spite of this page one appearance, it has earned five visitors in five months. This seems like a waste of time and money to refresh.
Identification Step-By-Step
So how do we approach identifying refreshes, assuming access to analytics and taking our new criteria into account?
Well, first, we’re going to do everything from the 101 process since the candidate identification process is intended to capture as much as possible before culling. But after that, we’re going to widen the net a little this way.
- Create a report or view that inventories month-over-month traffic to URLs on your site.
- Set a threshold for traffic decline of, say, 10% in three months. (You can vary this depending on your risk tolerance.)
- Filter the results to show you anything that has declined in this fashion.
- Add those URLs to the candidate list.
This is going to result in the following URLs in your candidate list:
- Anything with outdated years in the title.
- Anything ranking between positions 4 and 15 for its “best” keyword.
- Anything ranking in positions 1–3 for its “best” keyword that has seen a decline in traffic.
- Anything ranking below position 15 for its “best” keyword that has managed to earn traffic (probably because the keyword stats tool doesn’t know about its best keyword).
Prioritizing and Culling
With this candidate list, our culling process is going to look a bit different than the 101 scenario. For each candidate, remove it if any of these are true:
- The article with a year in the date is obviously about some temporal event.
- The article is unrelated to the keyword, and not earning traffic.
- It has less than some gross threshold of monthly traffic that you choose, and it either ranks below position 15 (no organic potential) or is on page 1 (little upside since it should already have traffic).
- The article has been modified in the last six months and isn’t declining (meaning if you published an article five months ago and it’s already peaked and started declining, you could refresh it).
Absent any other agenda you might have, I would suggest prioritizing by traffic volume of the primary target keyword.
The Rationale
What we’ve really done here is refine the 101 model to eliminate some false negatives (declining traffic in top positions) and false positives (low potential posts in “refreshable” positions).
So now, generally speaking, we’ll refresh content with significant but declining traffic. We’ll also refresh things with potential that aren’t too risky. And we’ll do this based on analytics data combined with quick SERP tool metrics rather than SERP tool metrics alone.
Refresh Identification 301: Reasoning about Expected Rank and Traffic
Now it’s time to fundamentally change the game. This section is both simpler (in terms of the identification process) and more advanced in terms of the underlying math and understanding of search intent.
Up to this point, we’ve used heuristics to nibble around the idea of how we might expect a post to perform on a given site, in an ideal situation. In other words, “ignore things below position 15 that have no traffic” is a crude approximation for “there’s no potential here, move on.” We’re really trying to refresh posts that are underperforming their potential.
So let’s just reason about potential traffic and refresh underperformers.
Reasoning About Expected Rank and Traffic
This is easy in concept and complex in execution. I should know because I’ve built a model that does this based on best fit over historical client data, and it involves exponents and logarithms. You could do something much simpler and, say, assume you’ll lose a SEPR position for every five “points” of keyword difficulty or some such.
Whatever you do, here’s a look at the data that you want to include, revisiting our “git without github” example on Make Me a Programmer.
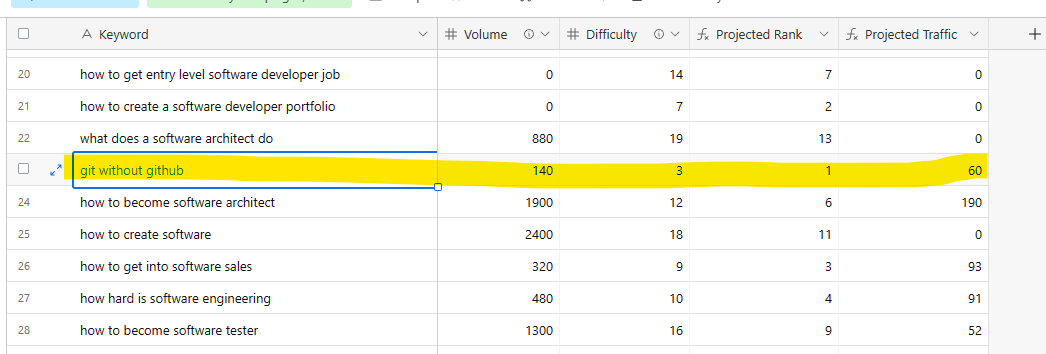
Notice two things about the highlighted term:
- Our model nails its expected rank.
- Our model understates its traffic potential. (This is common—I designed it to be pessimistic about traffic.)
So relying on our model, we would expect to rank #1 if we target this term. Through this lens, if we were in position 5 and had some traffic, we’d want to refresh since we were underperforming. We can also feel better about refreshing from position 1 to address declining traffic since we’re not punching above our weight and risking anything by touching it.
By contrast, look at the term “how to create software,” for which the model has the property ranking #11. Let’s say we’d targeted that term and were ranking 14th. We might not bother with a refresh because the expected outcome is still off of page 1, with zero traffic.
Alternatively, if we’d targeted “how to create software” and were ranking 6th and earning a bit of traffic, we might just want to let sleeping dogs lie. We’re already punching above our weight.
Identification Step-By-Step
Identification here throws the previous processes out, and it assumes both analytics and an ongoing concept of content and target keyword inventory. If you’re doing this for yourself, you should maintain a record of organic-targeting content you’ve created and the primary keyword targeted by that URL.
Here is what the candidate identification process will now look like:
- Identify any posts with past years in the title.
- Identify any posts with declining traffic above a certain threshold.
- Identify any posts that are underperforming projected rank after six months of time to cook since the last touch.
- (Optionally, if you’re risk tolerant) identify any posts that are hitting or exceeding expectations but are still ranking outside of the top three, and you really want to own that.
As I mentioned, the actual process here is FAR easier once you have the infrastructure in place. In fact, it’s not a lot of effort to simply have a refresh dashboard view of your content that you can look at any time you like.
Prioritizing and Culling
Again, we’re in fairly simple territory here, at least conceptually. You really don’t need to do any culling at all in this particular situation, since we’ve cut right to the meat of the issue with performance modeling.
However, you could prune the list a bit, if you were so inclined:
- If you find any posts that are fundamentally not addressing the search intent of their paired keyword and are just ranking because the search is easy or your authority is high, you can probably skip those.
- If the post’s traffic is declining because of declining topical interest and search volume rather than SERP competitors, you can probably skip those too.
Prioritization also looks a little different here. In a vacuum, I’d recommend prioritizing based on potential traffic gains for the refresh, measured either by decline from peak or, absent that, actual vs projected traffic for the primary keyword.
The Rationale
The rationale for the 301 approach is by far the easiest to explain. You’re surgically identifying the most potential for gain and thus the highest expected value for an intervention.
Refresh Identification Summary
If you’re still with me, you’ve read, or at least skimmed, through a pretty granular treatment of refresh parameters. As a reward, I’d like to close with a simple, high-level summary that all of the tactics here feed into. At the end of the day, here’s what you really need to do, in three steps:
- Establish a list of “don’t risk it” posts that are performing well and that you shouldn’t touch. This will depend on your risk tolerance.
- Establish a list of “don’t bother” posts that are either new or have low upside. This will depend on your budget and/or appetite for work.
- Refresh anything not on those lists, in order of the upside you perceive to refreshing.
As I’ve demonstrated, there’s no shortage of devil in the details, but if you’re using some flavor of this process, you’ll be in pretty good shape however you tackle it.
Oh, and by the way, if you’re interested in the 301 approach and our rank and traffic projections, just drop me a line. It’s proprietary-ish, but I’m not shy about using or sharing it, so if you’d like to project where you should rank for search terms, just let me know and we’ll get you set up (at least unless so many people ask for this that it becomes unwieldy).
